
Logging in Microservices
There are multiple ways to generate log in NodeJS, In this post we will see some of the ways.
- Using standards IO (to output log on console’s output stream)
- Using log file (write log on files)
Using standards IO (to output log on console’s output stream)
In this way, we just push the log onto the console’s output/error stream. we do not care where it will be stored.(generally we listen from process output stream and store all the data to either single log file(using some third party solution) or push data to ELK stack)
One way to push data to output stream is to use console.log , But rather then pushing data directly using console.log, its better to also push some meta data about each log(eg. time). We can do that using logging library available like winston, log4js etc.
This approach is very flexible because unlike storing data to file, you are just pushing logs to a stream, you don’t care how it will be processed further(stored on disk, pushed on ELK or just ignored).
This is also recommended way for handling logs in containerized microservices(eg. Docker), where it becomes very difficult to manage logs for all containers in single place.
Using log file (write log on files)
As the heading implies, we store our logs into file. You can use winston library to store the logs in file.
This gives us very traditional approach to logging, where all of our logs are stored in disk where we are running our application. This is good for any monolithic application, where you don’t want to add any times/resource for managing/getting insights from your logs.
Or you can use ELK stack with beats(filebeat for data collection)
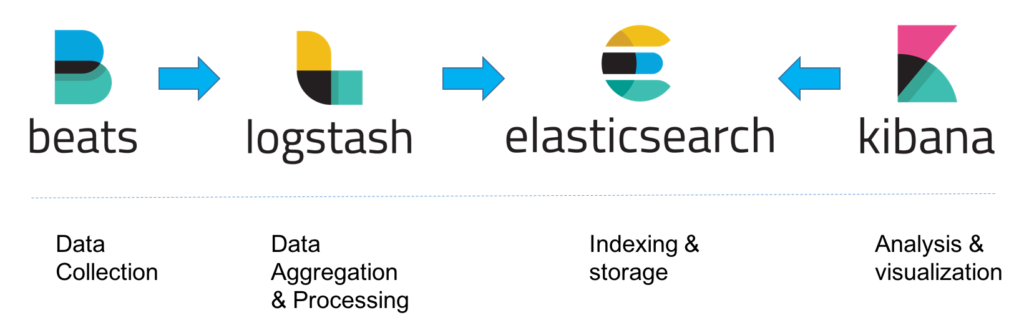
Thanks for reading.